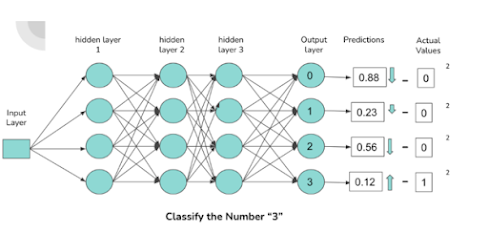
3.3.4 Deep Learning Frameworks

Deep learning frameworks are software libraries that provide the building blocks for creating and training neural networks. They abstract low-level details (like tensor operations and gradient computation) so developers can focus on model design and experimentation. Figure 1 illustrates a simple feedforward neural network with input, hidden, and output layers – the fundamental concept behind many deep learning models. Frameworks represent such models as computation graphs of tensor operations and automatically handle gradient backpropagation. For example, TensorFlow (pre-v2) builds a static graph at model definition time, whereas PyTorch uses a dynamic graph evaluated on the fly. This distinction – static vs. dynamic computation graphs – affects flexibility and performance of the framework. Figure 1: A simple feedforward neural network (ANN) with input, hidden, and output layers. Deep learning frameworks represent such architectures as computation graphs of tensor operations. De...